Discovering The World of Forensic Speech Analysis
Exploring the complex and fascinating world of Speech Analysis
The world of Forensic Speech Analysis is complex and fascinating. Risk Diversion and Phonexia offers a comprehensive portfolio of cutting-edge speech recognition and voice biometrics technologies ready to meet any commercial and governmental scenarios. Powered by the latest advancements in artificial intelligence, acoustics, phonetics, and voice biometrics science.
What is Forensic Speech Analysis?
Forensic speech analysis involves the detailed analysis of audio, from sources such as a phone call, voicemail message or covertly recorded conversation. This aims to produce a reliable phonetic profile of a speaker to determine their identity.
How does it work?
Phonexia Voice Inspector (VIN) is highly intuitive.
VIN offers several features that strongly support the work of voice forensic experts:
* A standalone application with a complete easy-to-use Graphical User Interface (GUI).
* Automatic comparison of questioned recording (unknown speaker recording) against a suspected reference speaker (group of recordings) with a known speaker i.e. 1:1 identification and 1:N identification.
* Implemented speech technologies: Speaker Identification, Speaker Diarization, Phoneme Recognizer, Voice Activity Detection and Speech Quality Estimation.
* A search for repetitive sound patterns across all recordings in audio due to the automatic phonemic transcription.
For VIN to analyse speech, population sets needed to be created. A population set must have at least ten (10) voice recordings of a specific language, with recordings being separated for men and women as well for young and old. Each voice recording gets its own voiceprint, like a fingerprint. For testing purposes, population sets for Afrikaans Male / Female, SA English Male / Female, and Sepedi Male were created. The population sets essentially calibrate VIN for that specific language, sex, and age groups.
Once the population sets are created, the next step is to look for a “suspect” voice recording. As an example, one found and used was of Gayton McKenzie, leader of the Patriotic Alliance, where he spoke in a restaurant in Afrikaans, with lots of background noise. A YouTube video where Mr. McKenzie had an interview in English with someone was also found and used with the video and audio were separated so that the audio could serve as the control voice recording (speaker’s voice recording).
In VIN, a case is created with accompanying descriptions; add the “suspect” voice recording to the case, create a speaker (who can be a suspect), select the population set, add the control voice recording(s) (YouTube audio), and then execute VIN.
What was the result in this case?
The result was astonishing, since one voice recording was in Afrikaans, and the other in English. VIN matched the two voice recordings as coming from the same person, despite the background noise from the restaurant and the two different languages.
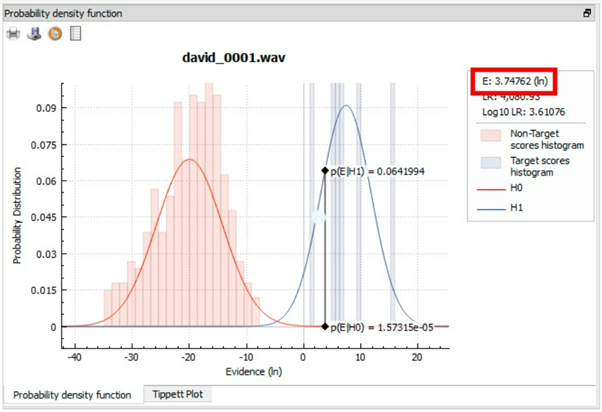
Above is an example of precious results, indicating a very good match.
The Evidence, i.e., the similarity score of the Questioned and Suspected speaker recordings, is the information of most interest. However, the Evidence itself is a score from the SID technology which is not necessarily calibrated for the specific case. To provide results in accordance with forensic science and practice, the Evidence is evaluated with respect to two complementary hypotheses:
Hypothesis 0: The Suspected speaker is not the source of the Questioned recording – this hypothesis is represented by the non-Target scores.
Hypothesis 1: The Suspected speaker is the source of the Questioned recording – this hypothesis is represented by the Target scores.
The Evidence value for a particular combination of a Questioned recording and Suspected Speaker is drawn as a black vertical line in the PDF plot, where it intersects with the Target and non-Target distribution curves, in blue and red, respectively.
What’s the conclusion?
There is a huge market for forensic speech analysis, and we are excited to unveil the latest version of Phonexia Voice Inspector—state-of-the-art voice comparison software specifically designed for forensic experts. Its fifth generation offers a significant leap in voice analysis accuracy, marking a significant milestone in the field of forensic voice comparison and speaker identification.
Risk Diversion Blog











